合抱之木,生於毫末;九層之臺,起於累土;千里之行,始於足下。
終於到這一步了, code generator 就是常聽到的程式碼產生器, 在編譯系統中, 就是用來產生組合語言。由於對 x86 32bit 模式比較熟悉, 我輸出的是 x86 32bit 的組合語言, 有點過時, 我知道; 現在都是 x64 耶! 我知道, 那你還用 x86 32bit, 就老人懶的學新東西嘛!
code generator 比直譯器難很多, 我想大家都知道, 但難上多少呢? 光四則運算的部份大概就是 1:20 這樣的難度, 只處理四則運算 (
Elementary arithmetic ) 就讓我花了不少時間, 也吃了不少苦頭, 遇到很多平常沒想到的細節。
如果還要加入變數的支援, 難度可能會來到 1:40, 相當難, 我已經簡化某些細節, 例如: 有號或是無號整數, signed, unsigned, 數字長度是 4 byte 還是 1 byte, 若把這些細節都考慮進來, 那得花很久的時間。對於開發編譯器的人, 我實在相當佩服。os kernel 的開發也很難, 他們屬於兩種不同的難, 並不會因為寫過 os kernel, 就讓學習編譯系統簡單些, 也是得從頭學習。
和 interpreter 一樣, 尋訪那個 AST, 在看到 1+2 時, 想辦法產生對應的組合語言, 說來簡單, 但光是加法就讓我絞盡腦汁才想出怎麼實作, 到了這步, 我刻意不參考任何書籍、網路資料, 我想測試一下自己的程度, 靠自己土砲出來, 很有成就感。原來我也寫的出來嘛!
以下是一些心得:
[暫時物件]
這不是指 c++ 的 "物件", 雖然在 c++ 書籍中很常聽到這個詞彙, 但直到我寫了 code generator 的四則運算, 我才真的體會到什麼是 "暫時物件"; 也不是指 "物件導向" 中的那個 "物件", 在寫 interpreter 就知道這個概念, 但那時還很模糊, 我現在有了新的體認。如果 "暫時物件" 迷惑了你, 那用 "中間結果" 這個詞彙也許更能貼近其意思。
1+2 在 interpreter 會產生一個暫時物件, 如果用 ASTNode 來存這個 3, 3 這個 ASTNode 就是運算 1+2 之後的暫時物件 (中間結果), 由於是 "暫時" 的而且也在記憶體佔據了空間, 所以要還回去, 重點來了, 該怎麼還, 什麼時候還呢?
哎呀, 真是難倒人, GC 就是在搞定這個, 我沒有提怎麼處理 interpreter 產生的暫時物件, 因為我根本沒處理。所以我那個玩具 c interpreter 會有 memory leak 的問題, 怎麼解, 交給 os gc 了。
但如果是在 code generator 上呢? 要如何產生這個暫時物件的程式, 又要產生歸還記憶體的程式碼呢? 沒 gc 那麼複雜, 比你想像中的還簡單。
mov $1, %eax
add $2, %eax
以 x86 32bit 組合語言為例子, 這樣就搞定 1+2, 疑! 暫時物件在哪裡? 這個例子不容易看出暫時物件 (因為根本就沒有暫時物件), 來看看下個例子:
1+2+5
mov $1, %eax
add $2, %eax
add $5, %eax
疑! 好像也沒看到暫時物件。
再看一個
(1+2)+(3+4)
1+2
mov $1, %eax
add $2, %eax
3+4
mov $3, %eax
add $4, %eax
eax 的值被覆蓋了, 這樣怎麼把他們加起來呢?
3+4 改用 ebx
mov $3, %ebx
add $4, %ebx
然後把 eax, ebx 加起來
add ebx, eax
有點
政治 程式敏感的人應該會開始覺得有點不對勁, 再來看下一個例子。
(1+2)+((3+4)+(5+6))
沒辦法很快寫出來吧
照前面的想法, 這個得用到 ecx 了, 如果有更長的運算式, 可能得用到 ezx 了, 但是 x86 沒有 ezx 可以用。暫存器也不是無限的, 回頭來看 1+2+5 的例子, 來看看引入暫時物件後的組合語言, 先算 1+2,
1+2+5
mov $1, %eax
add $2, %eax
然後產生暫時物件 3, 要把 3 存在哪裡呢? 都可以, 你想得到的地方都可以, 但其實選擇不多, 不是 stack 就是 heap。我選擇了 stack, 這樣比較容易釋放這個暫時物件。
push %eax # 把 3 這個暫時物件放到 stack, 再來做 +5 的動作。
pop %eax
add $5, %eax
這個組合語言很漂亮, 把暫時物件 3 所佔用的 stack 記憶體清掉 (因為 pop 出來了), 並做了剩下的 +5 計算。結束了嗎? 還沒, 產生的 8 (3+5) 也是暫時物件, 存到 stack 中吧!
push %eax
這時候的 stack 有一個 8 的暫時物件, 什麼時候要用到, 什麼時候要歸還這個 stack 佔用的記憶體, 就看程式碼怎麼寫, 以這個例子來說, 由於不用存到其他變數中, 就 pop 掉它吧。
由於產生的暫時物件我放在 stack, 所以在進入函式的開頭, 要產生留下這個 stack 空間的組合語言, 這可不容易, 要怎麼知道這個 stack 要留下多少 byte 呢? 當然要計算產生的暫時物件需要幾個 byte? 很難吧, 我放棄這部份的計算, 先 hard code 一個值。
光是搞定加法運算如: 1+2+5 就花了我很長的時間, 依樣畫葫蘆, 乘法沒那麼難了, 好不容易搞定 3*5*7, 來把他們組合起來, 1+2*3 馬上就出錯了, 讓我之前絞盡腦汁想的方法完全破功, 得從頭開始再想一個方法, 後來我又加入了 <, >, =, 複雜度又提高了。程式碼開始變得醜陋了。
比起 interpreter 的四則運算, code generator 的細節多很多, 很容易就產生錯誤的組合語言, 當然運算的結果也是錯的。
如果你用 gcc -S 看 1+2+5 產生後的組合語言程式碼, 肯定是看不到這樣的作法的, 因為 gcc 會很聰明的產生 8, 而不會如我說的產生那麼多組合語言, 若說 gcc 是聰明的 c compiler, 那我這個 simple c compiler 就是傻瓜編譯器, 他傻瓜我聰明。
另外有一個比較不傷腦筋的作法是完全使用 stack。
1+2+3
mov $1, %eax
mov $2, %ebx
push %eax
push %ebx
pop %ebx
pop %eax
add %eba, %eax
push %eax
mov 3, %ebx
push %ebx
pop %ebx
pop %eax
add %eba, %eax
把 1 和 2 push 到 stack, 然後做相加的動作, 再 push 到 stack, 再做 + 3 的動作, 這方法比較容易理解, 其實就是 postorder 或是 stack base machine 的作法, 我不想用這個作法, 看起來不厲害阿, 自己胡亂想了上述的方法。
看完暫時物件後, 再來看其他問題, 我把四則運算分為幾個部份:
immediate value
variable
type
[immediate value]
就是做 1+2 這種, 在暫時物件那段說完了。
[變數]
prog 1. 0 func1()
1 int c;
2 c=5;
3 c+2;
這種運算式就是用到了變數, 引入了變數會帶來很多問題, 這個變數在哪裡? 是 global 還是 local 變數。
所以要分配 c 的位址, 並且紀錄這個資訊, 這樣在 prog 1. L3 的 c+2 才知道 c 的位置是什麼, 才能去那個位址把值拿出來和 2 相加, 你肯定無法理解我的意思, 有興趣做一次看看吧!
一樣要用表格紀錄起來, 本科系的朋友應該知道這就是 symbol table, 陷阱在於, 在 function 開頭要保留 stack (eps = eps-4), 用來分配給 c 這個變數 (ebp-4 的位址保留給 c 變數)。
high address return address 上一個函式
new ebp old ebp (上一個 fcuntion 的 ebp) 的 stack frame
esp (esp-4 的 esp) c (epb-4) func1 的
stack frame
func1:
push %ebp
mov %esp, %ebp
subl $4, %esp # 留給 c 變數的記憶體空間
push %ebp 的行為: 先把 esp-4, 再把 %ebp 放入 stack
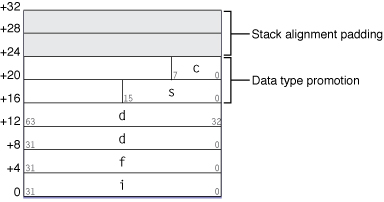
[型別大小]
int i
char x;
x = 5678; // 超過 255, 會做 implicit conversion, 5678 的值會被截掉
i=300;
x=20;
i+x; // 將 x 提升到 int 大小
節錄
Linux C 编程一站式学习 表 15.2 來說明, 在 c 語言的 3+5; statement 中的 3, 是什麼型別? int 嗎? unsigned int? char ? 到底是那個呢? 有組合語言經驗的朋友馬上就聯想到這和暫存器有關系, 我應該產生
mov $3, %ah
mov $3, %ax
mov $3, %eax
中的那個呢?
顆顆, 我沒考慮這問題, 直接產生 mov $3, %eax 這個版本, 這是對的嗎? 3 對應到表 15.2 的 1A 欄位, 3 用 int 就可以存起來, 所以 3 的型別就是 int,
1234U 呢? 自己看連結的內容吧, 我要表達的是四則運算的型別部份沒想像中的簡單, 在我的簡單版本中, 是完全不考慮這些的, 現在你可以體會我說的難度來到 1:40 感覺吧, 事實上還有 conversion, integer promotion 要處理, 很複雜的。我的版本還沒考慮 float/double。
表 15.2. 整数常量的类型
后缀 A 十进制常量 B 八进制或十六进制常量
1 无 int
int
2 u或U unsigned int
unsigned int
2 l或L long int
long int
4 既有u或U,又有l或L unsigned long int
unsigned long int
5 ll或LL long long int
long long int
6 既有u或U,又有ll或LL unsigned long long int
unsigned long long int
以上的幾個問題都被我部份簡化了, 但難度還是很高, code generator 真的不簡單。
最後, 終於來到最後了, 再忍耐一下, 這篇文章快結束了。
1 > 2 的 > 是輸出 cmp 這個指令, 雖然不是四則運算但是得提一下, 因為 if node 需要做 > 的運算, 所以要先支援 > 的 code gen, 才能處理 if node。
1 > 2 要產生什麼樣的組合語言呢? 難倒我也, gcc 編譯器依然不產生 1 > 2 的組合語言, 沒的抄, 我用了一個辦法得知這件事:
rel.c 1 int gr(int c)
2 {
3 return c<2;
4 }
gcc -m32 -S rel.c = rel.s 1 .file "rel.c"
2 .text
3 .globl gr
4 .type gr, @function
5 gr:
6 pushl %ebp
7 movl %esp, %ebp
8 cmpl $1, 8(%ebp)
9 setle %al
10 movzbl %al, %eax
11 popl %ebp
12 ret
13 .size gr, .-gr
14 .ident "GCC: (GNU) 5.4.0"
15 .section .note.GNU-stack,"",@progbits
終於得知要用 cmpl, setle 來得到 1 > 2 的運算結果:
1>2 得到 0
1<2 得到 1
這個 0, 1 是什麼 type 呢? C 標準規定要是 int, 所以要以 int 的大小回傳這個結果, 如果用 char type 來接 int 這個結果, 要做 implicit conversion, 別擔心, 我都沒做。